
唱作俱佳,腾讯AI艾灵领唱中国新儿歌
今年六一儿童节,腾讯联合北京荷风艺术基金会发起“腾讯荷风艺术行动”,给孩子们送上两份礼物,为音乐美学中国素质教育的发展做出贡献。
其中一份就是由首席儿歌守护唱作人,青年演员歌手王俊凯与雄安孩子,以及腾讯AI数字人艾灵共同演绎的新歌《点亮》。这份礼物被以特别的方式呈现:在H5互动里,每个人都可以轻松召唤AI艾灵,创作你的专属MV——给几个关键词,艾灵就能为你创作专属歌词,并和王俊凯一起唱给你听。
H5演示视频——推荐使用竖版 https://share.weiyun.com/15lbGUGn
在互动里,唱作俱佳的AI数字人艾灵已搭乘互联网来到每个人面前,她不仅能作词,还能用近乎真人的声线演唱,加上用多模态智能技术搭建的数字躯体,绝对是令你难忘的全能型虚拟歌手。
心动了吗?扫描下方二维码或点击“阅读原文”,制作一个你的新歌mv。

怎么样?是不是高音甜、中音准、低音稳?AI艾灵源自腾讯 AI Lab 的实验探索性技术项目——AI 数字人(Digital Human)。项目的目标是把计算机视觉、语音/歌声合成和转换、图像/视频合成和迁移、自然语言理解等多模态 AI 能力与技术深度融合,生成清晰、流畅、高质的可交互内容,打造高拟人度的智能数字人,推进 AI 在虚拟偶像、虚拟助理、在线教育、数字内容生成等领域的应用。
AI 艾灵使用了基于数据依赖型的深度学习方法,现在还只能生成基础歌词和合成歌曲,无法实现完全自由的创作。但腾讯 AI Lab 将继续技术攻坚,探索自动化音乐合成及基于全新乐曲自动生成歌词模板再自动填词的新方法。此外,基于智能数字人的交互式技术在音乐教育方面的应用也是重要的探索方向。
下面通过腾讯 AI Lab 的两项研究成果: DurIAN 个性化歌声合成 和 SongNet (相关论文被顶级会议 ACL 2020 收录) 来谈谈AI艾灵歌声背后的核心技术。
DurIAN个性化歌声合成
如果你用过早期的自动合成语音听书软件,那你就会听过最原始的机器合成语音,即直接将各个字词的发音生硬地拼接到一起,没有人类在自然说话和唱歌时自然起伏的韵律。很多电影也采用了人们对机器合成语音的这种典型印象来塑造机器人或 AI 角色,而且这类声音也是著名物理学家斯蒂芬·霍金偏爱的音色。
但是,随着近些年机器学习技术的发展,合成语音在拟真度方面已经取得了长足的进步,机器声再也不只是人类印象中那种一板一眼的刻板模样了,现在的 AI 甚至还能学会像人类一样情感充沛地歌唱!
快来听听这次在 QQ 音乐上线的公益数字专辑《儿歌新唱》里,AI艾灵与小朋友们的一起合唱的《声律启蒙》
QQ音乐链接《声律启蒙》 https://y.qq.com/n/yqq/song/002epGT73JjYUB.html?ADTAG=h5_playsong&no_redirect=1
想听更多歌曲,可以移步她的B站直播间:
AI艾灵的歌声即来源于这样的 AI 技术。首先,研究者以音素为基本发音单元将任意歌曲描述为一连串音素的序列;然后通过分析歌谱,从文字、旋律、节奏等多个维度分别提取和预测词曲中每个音素的发音、时长、停顿、音高、风格和演唱技巧等特征;最后使用由真人(中国网络声优龟娘)演唱的歌声训练得到的深度神经网络声学模型和声码器模型,合成出与真人声线高度相似歌声音频。
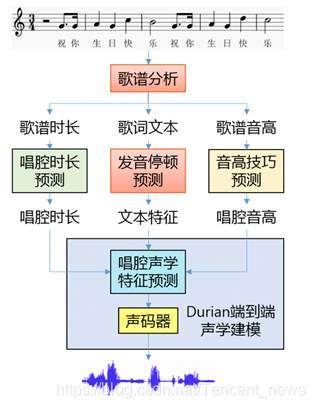
AI 歌声合成的模型架构
不同于“初音未来”等虚拟歌姬的“机器合成+人工调教”模式,使用了基于DurIAN声学模型 的AI艾灵无须经过人工调教就能得到非常自然和拟真的歌声。
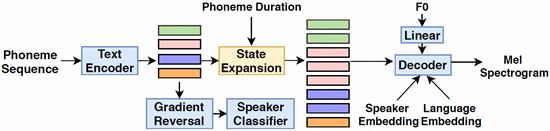
DurIAN-singing synthesis的声学模型结构
我们在端到端语音合成模型DurIAN的基础上进行修改,加入基频信息、说话人信息和语言信息来进行歌声合成的声学模型建模。该模型不仅可以从人的说话数据直接训练出唱歌模型,还可以实现跨语种歌声合成,比如用英文说话人的声音合成中文歌声。声学模型的编码器采用音素序列作为输入,编码器的输出经过一个对抗训练的说话人分类器以减少输入文本与说话人的相关度,提高最终合成音频的说话人相似度。与此同时,编码器的输出根据输入的唱腔时长信息沿时间轴展开,与输入的基频、说话人向量、语言向量进行拼接,作为解码器的输入,精准控制合成歌声的韵律、音调和音色。解码器采用自回归模型预测梅尔频谱。多频段同步式 WaveRNN 模型用作声码器从生成的梅尔频谱合成音频。这项技术已经可以在适当的硬件成本下实现实时歌曲合成。在互动中,AI艾灵可以快速地为千万用户输入的歌谱合成出对应的歌声。
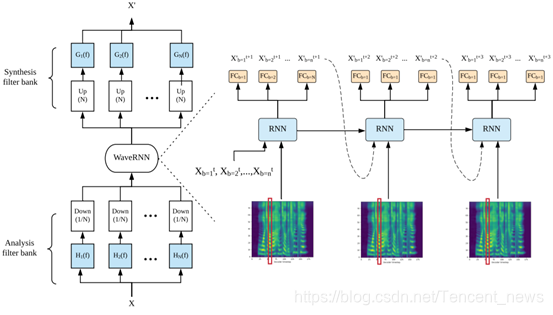
多频段同步式 WaveRNN:首先把语音信息分频段,每一步用同一个声码器模型同时预测多个频段的值,如果分成 4 个频段,则每一步可以计算 4个值,计算次数就是原来的四分之一。在合成过程中,声码器预测多频段的值后,通过上采样和专门的滤波器设计就能保证恢复没有失真的原始信号。
展望未来,这项技术可以用于降低歌曲制作过程中录音环节的成本,更可以用于打造虚拟偶像,成为广大专业和社区音乐人创作不可多得的制作工具。除了 AI 歌声合成技术之外,腾讯 AI Lab 还在研究数据量极小和录音质量差条件下的歌声合成。
SongNet:为你写歌
AI艾灵的歌词生成方案基于腾讯 AI Lab 最新研发的歌词创作模型SongNet。该深度学习模型最大的特点就是可以给定任意格式和模板来生成相契合的文本。在前文的H5里面,AI艾灵的"命题作词“技能就来源于此。
例如,给定《十年》这首歌词的格式,我们可以通过SongNet重新进行配词,并保证格式不变,可以根据原来的曲谱进行演唱:
原歌词:十年之前/我不认识你/你不属于我/我们还是一样/陪在一个陌生人左右/走过渐渐熟悉的街头
新配词:夜深人静/思念你模样/多少次孤单/想伴在你身旁/是什么让我如此幻想/为何会对你那般痴狂
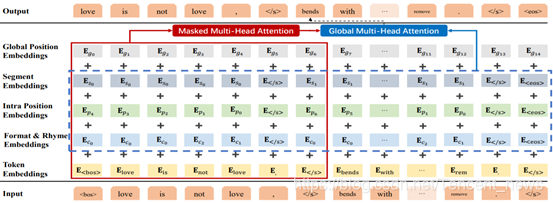
SongNet 模型框架
该任务的挑战在于既要生成跟格式一致的文本,又要保证句子的整体性,还要有歌词的韵律以及美感。所以我们设计了SongNet模型来尝试一次性解决所提到的问题。SongNet模型的基本骨架是一个基于Transformer的自回归语言模型,我们针对格式、韵律、句子完整性设计了特殊的符号来进行标识和建模。通过局部和全局两种注意力机制达到了对上下文语义和格式同时建模的目的。SongNet模型兼有全局生成和局部精修两种功能,通过主题和类型控制全局生成整段歌词之后,由于模型的局限性,总会有差强人意的部分。这时我们就可以和模型进行交互,将质量不高的词句抹掉让模型局部重新生成补全以达到精修的目的。词粒度和句粒度的MASKing训练策略可以进一步增强模型给定上下文补全缺失内容的能力。
此外,SongNet 也采用了类似于 BERT 和 GPT 的预训练和微调范式,通过在大规模文本语料的预训练和歌词语料的微调过程,可以进一步提升模型生成歌词的质量。

SongNet 根据给定格式填词(宋词和十四行诗)

SongNet 根据给定内容局部补全精修
在“王俊凯AI唱我的歌”H5 中,用户随机输入一个或者多个关键词,AI 就可以根据这份灵感,创作出优美、恰当的歌词,比如“田野花开多芬芳,仰望满天星光”、“青草地里看花开,小花倾听着爱”。
生成的歌词然后会被提交给歌声合成模块,再融合对应的背景音乐,一首悦耳动听的歌曲就新鲜出炉了。
SongNet模型是AI Lab在AI创作方向的一次尝试,现阶段模型也存在一些局限性。歌曲作为一种艺术形式,蕴含了人类细腻的情感和深厚的智慧,在这方面目前版本的模型和人类还有很大的距离,无法感知人类丰富多变的情感。而且此次还同时设置了上下文约束和蕴含特定关键词的限制,所以会在一定程度上降低模型生成歌词的逻辑性和连贯性。未来,我们一方面会持续增强模型对歌曲主题和情感的感知度,另一方面也会设计模型策略来进一步提升生成的歌词的逻辑性、连贯性以及优美度。
顺带一提,AI艾灵还能借助腾讯 AI Lab 研发的王者荣耀游戏解说生成模型来生成游戏解说词,再通过语音合成实时生成生动活泼的解说。
一起探索数字内容生成,共创未来
腾讯 AI Lab 已经通过公开论文发布了 DurIAN 和 SongNet 的技术细节,SongNet 代码也已开源,你可基于此开发自己的虚拟歌手或使用开源代码构建自己的写歌或写诗机器人,共同探索数字内容生成与教育等现实场景的结合方式,创造更多"科技向善“的可能性。
DurIAN论文:https://tencent-ailab.github.io/durian(投稿于INTERSPEECH 2020) SongNet论文:https://arxiv.org/abs/2004.08022(已被 ACL 2020 接收) SongNet代码:http://github.com/lipiji/SongNet

扫码关注w3ctech微信公众号
共收到0条回复